Algoritma K-Means++ Clustering adalah salah satu algoritma yang digunakan untuk klasifikasi atau pengelompokan data. Contoh yang dibahas kali ini adalah mengenai penentuan jurusan siswa berdasarkan nilai skor siswa.
Algoritma ini merupakan pengembangan dari Algoritma K-Means Clustering. Perbedaan algoritma ini dengan algoritma sebelumnya, dimana pada algoritma sebelumnya, cara memasukkan data pertama kali ke dalam cluster kosong adalah dengan cara acak. Sedangkan pada algoritma ini, memasukkan data pada setiap cluster menggunakan perhitungan jarak tertentu, sehingga tidak lagi dengan sistem acak. Sisa perhitungannya sama seperti algoritma pendahulunya.
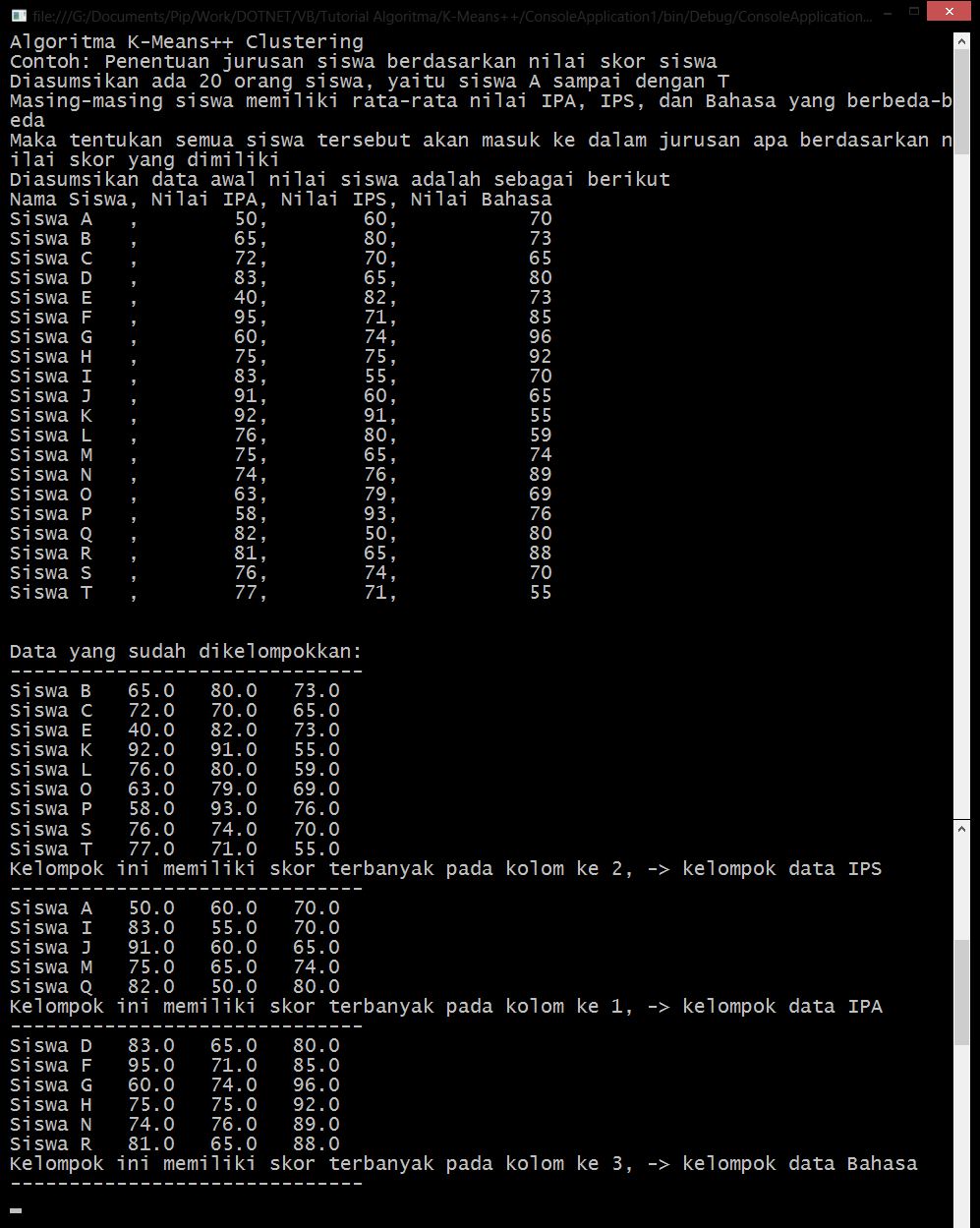
Diasumsikan ada 20 orang siswa, yaitu siswa A sampai dengan T
Masing-masing siswa memiliki rata-rata nilai IPA, IPS, dan Bahasa yang berbeda-beda
Maka tentukan semua siswa tersebut akan masuk ke dalam jurusan apa berdasarkan nilai skor yang dimiliki
Diasumsikan data awal nilai siswa adalah sebagai berikut
| Nama Siswa | Nilai IPA | Nilai IPS | Nilai Bahasa |
|---|---|---|---|
| Siswa A | 50 | 60 | 70 |
| Siswa B | 65 | 80 | 73 |
| Siswa C | 72 | 70 | 65 |
| Siswa D | 83 | 65 | 80 |
| Siswa E | 40 | 82 | 73 |
| Siswa F | 95 | 71 | 85 |
| Siswa G | 60 | 74 | 96 |
| Siswa H | 75 | 75 | 92 |
| Siswa I | 83 | 55 | 70 |
| Siswa J | 91 | 60 | 65 |
| Siswa K | 92 | 91 | 55 |
| Siswa L | 76 | 80 | 59 |
| Siswa M | 75 | 65 | 74 |
| Siswa N | 74 | 76 | 89 |
| Siswa O | 63 | 79 | 69 |
| Siswa P | 58 | 93 | 76 |
| Siswa Q | 82 | 50 | 80 |
| Siswa R | 81 | 65 | 88 |
| Siswa S | 76 | 74 | 70 |
| Siswa T | 77 | 71 | 55 |
Langkah pertama adalah memasukkan data-data yang digunakan.
Contoh data awal adalah sebagai berikut:
Dim atribut() As String = {"IPA", "IPS", "Bahasa"}
Dim data(19)() As Double
data(0) = New Double() {50, 60, 70}
data(1) = New Double() {65, 80, 73}
data(2) = New Double() {72, 70, 65}
data(3) = New Double() {83, 65, 80}
data(4) = New Double() {40, 82, 73}
data(5) = New Double() {95, 71, 85}
data(6) = New Double() {60, 74, 96}
data(7) = New Double() {75, 75, 92}
data(8) = New Double() {83, 55, 70}
data(9) = New Double() {91, 60, 65}
data(10) = New Double() {92, 91, 55}
data(11) = New Double() {76, 80, 59}
data(12) = New Double() {75, 65, 74}
data(13) = New Double() {74, 76, 89}
data(14) = New Double() {63, 79, 69}
data(15) = New Double() {58, 93, 76}
data(16) = New Double() {82, 50, 80}
data(17) = New Double() {81, 65, 88}
data(18) = New Double() {76, 74, 70}
data(19) = New Double() {77, 71, 55}
Sebelum masuk kedalam langkah-langkah pembahasan algoritma, ada beberapa konstanta atau parameter yang harus diketahui, yaitu:
* Tentukan Jumlah Iterasi
Diasumsikan dalam kasus ini, jumlah iterasi adalah 100
Dim jumlahIterasi As Integer = 100
Langkah-langkah penggunaan algoritma ini adalah
* Lakukan proses pengelompokan data menggunakan algoritma ini
Penjelasan lebih detail tentang fungsi ini dapat dilihat pada penjelasan skrip dibawah ini (poin 1 – 5)
Dim daftarCluster() As Integer = Cluster(data, jumlahCluster, jumlahAtribut, jumlahIterasi)
Memasuki perhitungan utama pada fungsi Cluster
1. Lakukan normalisasi data agar data dengan angka yang terlalu besar tidak mendominasi pengelompokan data
Normalisasi data dihitung dengan (rumus data – (rata-rata kriteria tersebut)) / standar deviasi kriteria tersebut
Rata-rata adalah jumlah semua data dibagi dengan jumlah datanya
Standar deviasi adalah akar dari ((kuadrat dari (jumlah dari (data – rata-rata))) / jumlah data)
1a. Salin data pada sebagai nilai awal jawaban data
Dim dataAwal As Double()() = New Double(data.Length - 1)() {}
For i As Integer = 0 To data.Length - 1
dataAwal(i) = New Double(data(i).Length - 1) {}
Array.Copy(data(i), dataAwal(i), data(i).Length)
Next
1b. Hitung nilai rata-rata tiap-tiap kolom
yaitu dengan rumus: jumlah semua data dibagi dengan jumlah datanya
Dim total As Double = 0.0 For i As Integer = 0 To dataAwal.Length - 1 total += dataAwal(i)(j) Next Dim rata2 As Double = total / dataAwal.Length
1c. Hitung nilai standar deviasi tiap-tiap kolom
yaitu dengan rumus: akar dari ((kuadrat dari (jumlah dari (data – rata-rata))) / jumlah data)
Dim totalKuadrat As Double = 0.0 For i As Integer = 0 To dataAwal.Length - 1 totalKuadrat += (dataAwal(i)(j) - rata2) * (dataAwal(i)(j) - rata2) Next Dim stdDev As Double = totalKuadrat / dataAwal.Length
1d. Nilai akhir dihitung dengan rumus (data dikurangi rata-rata) dibagi nilai standar deviasi
For i As Integer = 0 To dataAwal.Length - 1 dataAwal(i)(j) = (dataAwal(i)(j) - rata2) / stdDev Next
2. Ini adalah fungsi utama dari algoritma K-Means++
Tentukan centroid / mean awal pada masing-masing cluster
Penjelasan lebih detail tentang fungsi ini dapat dilihat pada penjelasan skrip dibawah ini (poin 2a – 2b)
Dim means As Double()() = HitungMeansAwal(jumlahCluster, dataAwal)
Memasuki perhitungan utama pada fungsi HitungMeansAwal
2a. Ambil data pertama secara acak
Cata data dengan indeks ini sebagai data yang sudah terpakai
Dim rnd As New Random(0) Dim idx As Integer = rnd.[Next](0, data.Length) Array.Copy(data(idx), means(0), data(idx).Length) isTerpakai.Add(idx)
2b. Lakukan perhitungan untuk setiap k mean berikutnya
2b1. Lakukan perulangan pada masing-masing data
2b1a. Hitung jarak dari masing-masing data pada mean ke k
Dim daftarJarak As Double() = New Double(k - 1) {}
For j As Integer = 0 To k - 1
daftarJarak(j) = HitungJarak(data(i), means(k))
Next
* Gunakan fungsi ini untuk menghitung jarak dari data dan centroid / mean
metode yang digunakan adalah jarak Euclidean, dengan rumus akar dari (jumlah dari (kuadrat dari (data – centroid)))
Private Function HitungJarak(data As Double(), mean As Double()) As Double Dim jumlahKuadratDariSelisih As Double = 0.0 For j As Integer = 0 To data.Length - 1 jumlahKuadratDariSelisih += Math.Pow((data(j) - mean(j)), 2) Next Return Math.Sqrt(jumlahKuadratDariSelisih) End Function
2b1b. Hitung nilai kuadrat jarak pada data ini dengan rumus kuadrat jarak dari jarak terpendek
Dim m As Integer = indeksDataTerendah(daftarJarak) kuadratJarak(i) = daftarJarak(m) * daftarJarak(m)
* Gunakan fungsi ini untuk mencari indeks dengan nilai data terendah
Penjelasan lebih detail tentang fungsi ini dapat dilihat pada penjelasan skrip dibawah ini
Private Function indeksDataTerendah(daftarJarak As Double()) As Integer Dim idxMin As Integer = 0 Dim jarakTerpendek As Double = daftarJarak(0) For k As Integer = 0 To daftarJarak.Length - 1 If daftarJarak(k) < jarakTerpendek Then jarakTerpendek = daftarJarak(k) idxMin = k End If Next Return idxMin End Function
Tentukan data yang akan diambil pada mean ke k
Metode yang digunakan mirip dengan seleksi roulette (roulette wheel selection)
2b2. Hitung total kuadrat jarak untuk digunakan pada perhitungan probabilitas kumulatif
Dim totalKuadratJarak As Double = 0.0 For i As Integer = 0 To kuadratJarak.Length - 1 totalKuadratJarak += kuadratJarak(i) Next
2b3. Hitung probabilitas kumulatif
probabilitasKumulatif += kuadratJarak(idxData) / totalKuadratJarak
2b4. Jika nilainya lebih dari nilai acak, maka gunakan data ini sebagai mean berikutnya
If probabilitasKumulatif >= p AndAlso isTerpakai.Contains(idxData) = False Then idxTerpakai = idxData isTerpakai.Add(idxTerpakai) Exit While End If
2b5. Jika tidak maka, maka hitung kembali probabilitas kumulatif untuk data berikutnya pada perulangan berikutnya
idxData += 1 If idxData >= kuadratJarak.Length Then idxData = 0 batasPerulangan += 1
2b6. Masukkan data dengan indeks terpilih sebagai jawaban mean ke k
Array.Copy(data(idxTerpakai), means(k), data(idxTerpakai).Length)
Lakukan perulangan selama masih ada data yang berpindah cluster dan iterasi masih kurang dari batas perulangan (poin 3 dan 4)
3. Pindahkan semua data yang harus berpindah ke cluster lain
Kemudian tentukan apakah ada data yang berpindah cluster
Penjelasan lebih detail tentang fungsi ini dapat dilihat pada penjelasan skrip dibawah ini (poin 3a – 3d)
bPindahCluster = UpdateCluster(dataAwal, daftarCluster, means)
Memasuki perhitungan utama pada fungsi UpdateCluster
3a. Lakukan perhitungan pada masing-masing data
3a1. Hitung jarak pada masing-masing cluster
For k As Integer = 0 To jumlahCluster - 1 daftarJarak(k) = HitungJarak(data(i), means(k)) Next
3a2. Pilih cluster dengan jarak terpendek
Dim clusterBaru As Integer = indeksDataTerendah(daftarJarak)
3a3. Jika nilai cluster yang baru berbeda dari cluster sebelumnya, maka pindahkan data ini ke cluster yang baru
If clusterBaru <> daftarClusterBaru(i) Then bPindahCluster = True daftarClusterBaru(i) = clusterBaru End If
3b. Jika tidak ada data yang berpindah cluster, maka hentikan perhitungan
If bPindahCluster = False Then Return False
3c. Lakukan pengecekan terhadap cluster yang baru
Apabila perpindahan cluster menyebabkan salah satu cluster tidak memiliki data maka hentikan perhitungan
Dim jumlahDataPerCluster As Integer() = New Integer(jumlahCluster - 1) {}
For i As Integer = 0 To data.Length - 1
Dim cluster As Integer = daftarClusterBaru(i)
jumlahDataPerCluster(cluster) += 1
Next
For k As Integer = 0 To jumlahCluster - 1
If jumlahDataPerCluster(k) = 0 Then Return False
Next
3d. Simpan cluster baru sebagai jawaban cluster
Array.Copy(daftarClusterBaru, daftarCluster, daftarClusterBaru.Length)
4. Hitung ulang nilai masing-masing atribut pada masing-masing mean
Kemudian tentukan apakah semua cluster memiliki setidaknya 1 data?
Penjelasan lebih detail tentang fungsi ini dapat dilihat pada penjelasan skrip dibawah ini (poin 4a – 4c)
bTidakAdaClusterData0 = UpdateMeans(dataAwal, daftarCluster, means)
Memasuki perhitungan utama pada fungsi UpdateMeans
4a. Lakukan pengecekan jumlah data pada masing-masing cluster
Apabila ada cluster yang tidak memiliki data awal maka hentikan perhitungan
Dim jumlahCluster As Integer = means.Length
Dim jumlahDataPerCluster As Integer() = New Integer(jumlahCluster - 1) {}
For i As Integer = 0 To data.Length - 1
Dim cluster As Integer = daftarCluster(i)
jumlahDataPerCluster(cluster) += 1
Next
For k As Integer = 0 To jumlahCluster - 1
If jumlahDataPerCluster(k) = 0 Then
Return False
End If
Next
4b. Lakukan perulangan untuk setiap data
Hitung jumlah nilai untuk masing-masing kriteria
For i As Integer = 0 To data.Length - 1 Dim cluster As Integer = daftarCluster(i) For j As Integer = 0 To data(i).Length - 1 means(cluster)(j) += data(i)(j) Next Next
4c. Bagi jumlah nilai dengan jumlah data per cluster untuk masing-masing atribut
For k As Integer = 0 To means.Length - 1 For j As Integer = 0 To means(k).Length - 1 means(k)(j) /= jumlahDataPerCluster(k) Next Next
5. Tampilkan semua data yang sudah dimasukan ke dalam cluster
Hitung nilai skornya untuk masing-masing kriteria dalam cluster tersebut
Ambil nilai skor tertinggi sebagai jawaban jurusan yang seharusnya diambil
Dim st() As Boolean = New Boolean() {False, False, False}
For k As Integer = 0 To jumlahCluster - 1
Dim skor(jumlahCluster - 1) As Double
For i As Integer = 0 To data.Length - 1
If daftarCluster(i) = k Then
Console.Write("Siswa " & Chr(i + 65) & vbTab)
For j As Integer = 0 To data(i).Length - 1
Console.Write(data(i)(j).ToString("F1").PadLeft(6) & " ")
If st(j) = False Then skor(j) += data(i)(j)
Next j
Console.WriteLine("")
End If
Next i
Dim maks As Double = Double.MinValue
Dim idxmaks As Integer = -1
For i As Integer = 0 To jumlahCluster - 1
If maks < skor(i) Then
maks = skor(i)
idxmaks = i
End If
Next
Console.WriteLine("Kelompok ini memiliki skor terbanyak pada kolom ke " & idxmaks + 1 & ", -> kelompok data " & atribut(idxmaks))
Console.WriteLine("------------------------------")
Next k
Hasil akhir adalah: (klik untuk perbesar gambar)
Contoh modul / source code dalam bahasa VB (Visual Basic) dapat didownload disini:
Jika membutuhkan jasa kami dalam pembuatan program, keterangan selanjutnya dapat dilihat di Fasilitas dan Harga
Jika ada yang kurang paham dengan langkah-langkah algoritma diatas, silahkan berikan komentar Anda.
Selamat mencoba.
Saya butuh perhitungan secara manual tentang k-mea s ++ .apa kah admin bisa membantu. Berapa tarif nya min
Jika anda tertarik untuk menggunakan jasa kami maka silahkan menghubungi kami dengan nomor kontak yang tersedia pada halaman hubungi kami https://piptools.net/hubungi-kami/
Halo, saat ini saya sedang melakukan penelitian menggunakan algoritma k-means++, namun saat ini saya masih kesulitan memahami perhitungannya, khususnya pada perhitungan manualnya. Jika berkenan, apakah saya boleh meminta contoh perhitungan algoritma k-means++ dengan excel? Terima kasih
Algoritma KMeans++ merupakan salah satu algoritma yang cukup kompleks disebabkan adanya berbagai perulangan yang perlu dilakukan, sehingga alur perhitungannya menurut saya tidak bisa dijelaskan dalam bentuk dokumen excel.